Abstract
Accurate and interpretable evaluation of vision–language models (VLMs) is critical for tasks that require both reliability and transparency, such as automotive damage assessment, where structured outputs facilitate reliable decision making. This paper proposes CarDamageEval, a dual-layer evaluation framework that evaluates both structural accuracy and semantic quality in VLM outputs. The framework specifies a predefined structured format consisting of explicit tuples of damage type, vehicle body part and severity level, enabling systematic quantitative evaluation through pair-matching metrics such as precision, recall and F1 score. In addition, semantic quality is evaluated using the Holistic Description Score (HDS), which assesses correctness, completeness, coherence and relevance. These two layers of evaluation are combined within_ the hybrid CarDD Score, which provides a balanced metric that captures both factual accuracy and descriptive clarity. To enable structured evaluation, we constructed a dataset from public vehicle images, annotated with bounding boxes and linked damage type, body part and severity labels. Baseline experiments show that the framework effectively distinguishes model performance across different settings, highlighting the value of fine-tuning for producing accurate and structured damage descriptions. Although designed for automotive assessment, the principles underpinning CarDamageEval are transferable to other structured vision–language tasks, including lesion detection in medical imaging and defect localisation in industrial inspection, positioning it as a versatile and reusable evaluation standard.
Methodology of Evaluation Framework
The core challenge in evaluating vision–language models for automotive damage assessment lies in their tendency to generate free-form text that lacks structural consistency. Such outputs often omit critical attributes, misrepresent damage details, or provide descriptions that are difficult to verify against ground-truth annotations. This limitation prevents the use of conventional captioning metrics and complicates rigorous comparison across models. A reliable evaluation framework must therefore ensure that outputs conform to a predefined schema while also retaining semantic quality for practical use. The CarDamageEval framework addresses this challenge by introducing a dual-layer methodology. The first layer enforces structured prediction, where outputs are formalised as triplets of damage type, vehicle body part, and severity level. A matching operator compares predicted triplets with ground-truth annotations, and performance is quantified through precision, recall, F1 score, and accuracy. The second layer complements this structural evaluation with semantic quality assessment. Using the Holistic Description Score (HDS), generated narratives are evaluated on four dimensions: correctness, completeness, coherence, and relevance. This ensures that outputs are not only structurally accurate but also contextually meaningful and human-readable. To integrate both perspectives, the framework introduces the CarDD_Score, a hybrid metric computed as the harmonic mean of the F1 score and HDS. This design penalises imbalances and rewards models that achieve both factual correctness and descriptive clarity. The resulting methodology provides a rigorous, reproducible, and model-agnostic evaluation protocol, applicable not only to automotive assessment but also to other structured vision–language tasks such as lesion detection in medical imaging and defect localisation in industrial inspection.
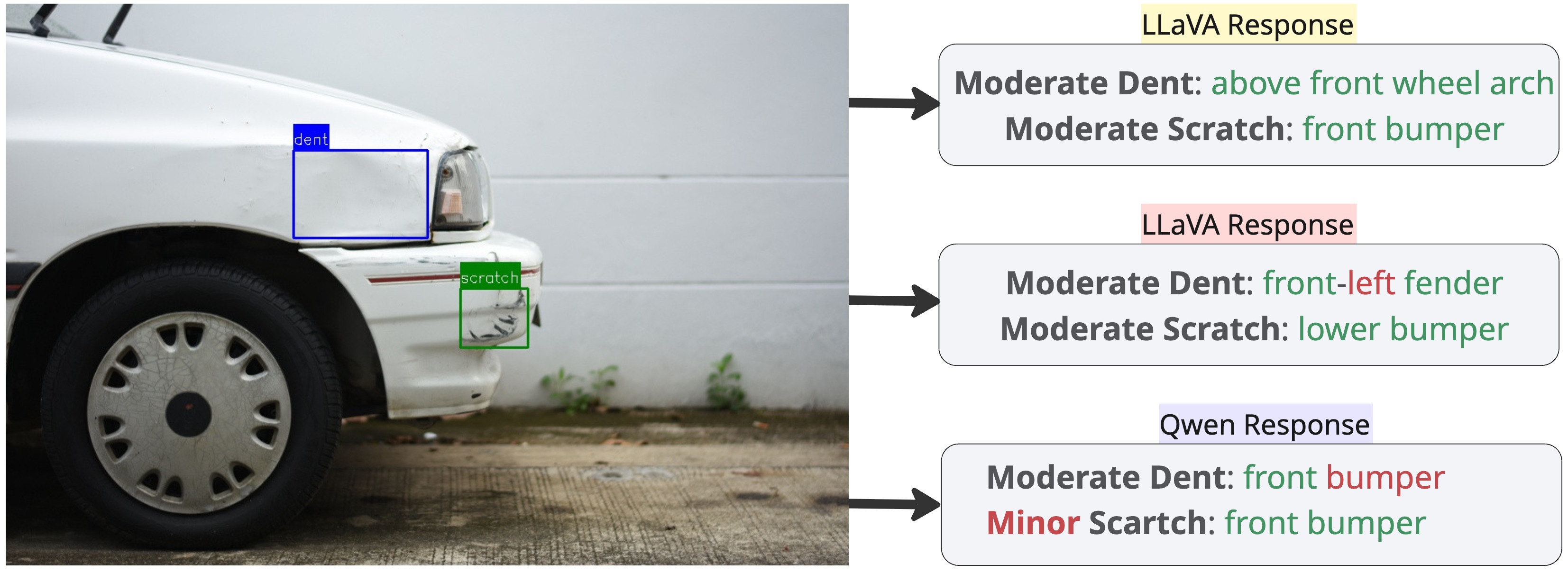
Figure: Qualitative Comparison of Structured Outputs from Fine‑Tuned VLMs. Green text denotes correct predictions, whereas red text marks incorrect outputs.