Abstract
Reliable vehicle damage assessment is critical for automotive e-commerce platforms, where buyers depend on clear visual evidence to make informed decisions. This work presents CarDVLM, a multimodal recognition framework that integrates an object detector with a fine-tuned vision–language model. The system identifies and localises damage in vehicle images, then produces structured, query-driven textual descriptions specifying the type, location, and severity of the damage. To enable training and evaluation, a comprehensive dataset is assembled from public and private sources, including annotated bounding boxes and semantically aligned textual labels. Model performance is measured using CarDamageEval, a dual-layer framework that combines structured pair-matching with semantic assessments of correctness, coherence, completeness, and relevance. CarDVLM achieves superior results compared with leading baselines (ChatGPT, Qwen, LLaMA), reaching an F1 score of 0.89 on structured metrics and an HDS score of 0.85 on semantic metrics. The model demonstrates consistent accuracy across damage types, vehicle body regions, and severity levels. Ablation experiments further validate its ability to detect both clearly visible and spatially complex damage under realistic operational conditions.
Model
CarDVLM adopts a targeted encoding strategy rather than full-frame analysis. Input images are first processed by GroundingCarDD, which produces bounding boxes and colour-coded class labels that are embedded as patch-level tokens while preserving spatial context. A trainable MLP projects these visual features into the embedding space of a frozen CLIP encoder, which is aligned with a frozen LLaMA-2 13B model equipped with LoRA adapters for efficient multimodal fine-tuning. Cross-attention links user queries to grounded regions, allowing phrases such as “dent on the rear bumper” to map to visual tokens. LoRA enables domain-specific reasoning over damage type, location, and severity while keeping core weights frozen, with training conducted for eight epochs using AdamW (learning rate 2e-4) and gradient checkpointing to reduce memory usage.
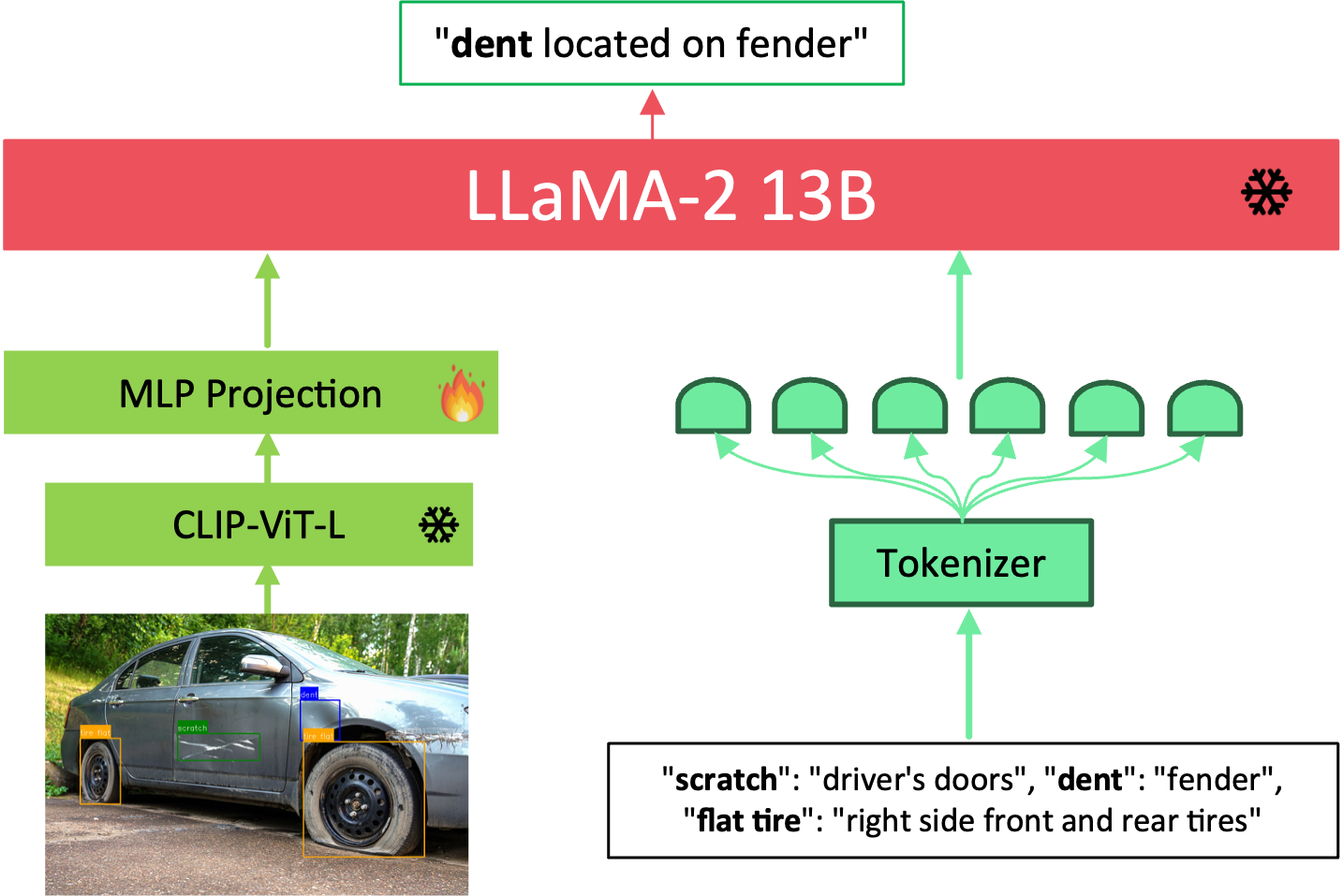
Overview of CarDVLM architecture